A special issue of RIDE
Call for Reviews
CollateX
and experiments with CollateX
- 1.a. Short intro to CollateX
- 1.b. Demo / hands-on
- 2. Identifying categories of variants
Collation
comparison of two or more texts in order to find similarities and differencesSemi-automated collation
since the '60sPrerequisites
digital textsTools
Among the most used ...
- Juxta Commons
- CollateX (Java | Python)
Gothenburg's model
Cost Action Interedition, 2009
(Juxta + CollateX)
- Tokenization
- Normalization
- Alignment
- Analysis and feedback
- Visualization
CollateX resources
- Website https://collatex.net/
- Tutorial https://github.com/DiXiT-eu/collatex-tutorial
- Python release https://pypi.org/project/collatex/
- Dekker, Ronald Haentjens, Dirk van Hulle, Gregor Middell, Vincent Neyt, and Joris van Zundert. 2015. “Computer-Supported Collation of Modern Manuscripts: CollateX and the Beckett Digital Manuscript Project.” Digital Scholarship in the Humanities 30 (3): 452–70. https://doi.org/10.1093/llc/fqu007.
- Dekker, Ronald Haentjens, and Gregor Middell. 2011. “Computer-Supported Collation with CollateX: Managing Textual Variance in an Environment with Varying Requirements.” In Supporting Digital Humanities (University of Copenhagen, 17-18 November 2011).
Demo / hands-on
- try the Demo on CollateX website https://collatex.net/demo/
- (if you have Python3 on your machine) try the Python version. Follow the installation instructions and use the sample data and scripts provided in the Github repo
Substantive vs formal
(graphic and phonetic)
variants
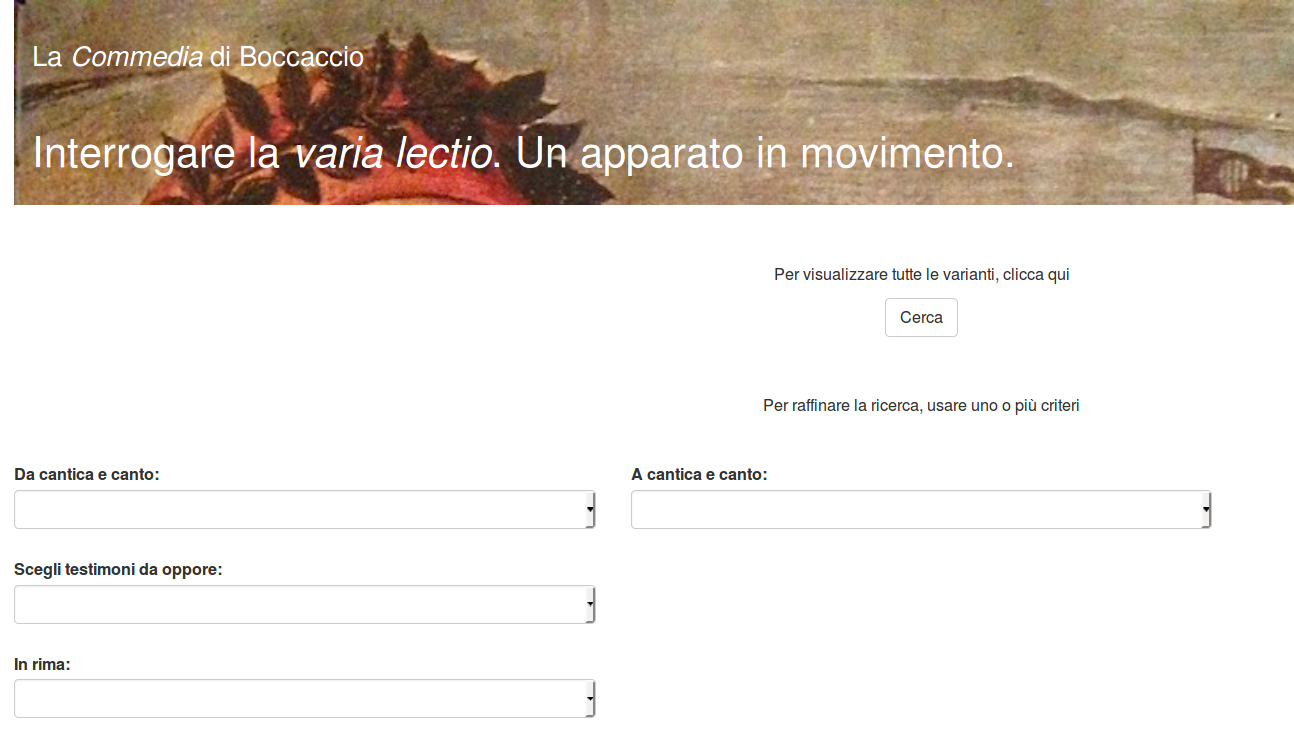 http://boccacciocommedia.unil.ch
http://boccacciocommedia.unil.ch
Silva, Georgette, and Harold Love. 1969. “The Identification of Text Variants by Computer.” Information Storage and Retrieval 5 (3): 89–108.
Robinson, Peter. Collate
- dictionary, defvars
- fuzzy match
1991, annunciato nella lista di diffusione Humanist
(dhhumanist.org/Archives/Virginia/v04/1240.html)
(dhhumanist.org/Archives/Virginia/v04/1240.html)
Robinson, P. M. W. 1989. “The Collation and Textual Criticism of Icelandic
Manuscripts (1): Collation.” Literary and Linguistic Computing 4 (2): 99–105.
Manuscripts (1): Collation.” Literary and Linguistic Computing 4 (2): 99–105.